Java JSON解析特性分析
JSON是一种轻量级资料交换格式,其内容由属性和值所组成,因此也有易于阅读和处理的优势,JSON也是目前最为流行的C/S通讯方式。JavaEE的规范中制定了Java API for JSON Processing (JSON-P,JavaEE7+)和Java API for JSON Binding (JSON-B,JavaEE8+)规范,但是在JavaEE的request中无法直接获取JSON请求中的参数,需要借助MVC框架和第三方JSON解析库。
0x00 研究JSON解析特性的重要性
随着前后端分离的开发方式的兴起,基于JSON的请求变得越来越流行。为了能够防御来自JSON请求参数中的恶意攻击,WAF和RASP都逐渐的支持了JSON参数解析。也许是因为Java语言没有官方的JSON解析库,因此诞生了非常多的第三方JSON解析库,它们被广泛的运用于不同Web应用中,其中不乏号称性能天下第一、用户体量巨大且长期存在安全问题的fastjson(俗称bugson)。
JSON反序列化攻击是目前最为主流的JSON请求攻击方式,很少有人关注过JSON解析本身所包含的特性所带来的安全问题。
RASP和WAF为了能够支持JSON解析就必然会选择(自实现?)JSON解析库,但是如果我们一旦找出其使用的库存在的解析问题后就可以轻松绕过防护,即可轻松绕过基于参数解析的WAF和RASP部分依赖请求参数的防护功能。
似乎在大多数人的潜意识中已经认定了Java中的JSON解析库都会按照某一个标准去解析(fastjson第一个不服),因此不会存在什么安全风险,本文将从JSON解析的细节(不包含反序列化攻击)来讲解JSON解析库的特性,让我们进一步的去了解不同的解析库所带来的巨大差异。
JSON解析库列表:
| 名称 | 描述 |
|---|---|
| gson | gson是google开源的Java JSON解析库,也是如今主流的JSON解析库之一 |
| jackson | jackson是开源的高性能JSON解析库,也是Spring MVC默认使用的JSON解析库 |
| fastjson | fastjson是阿里开源的JSON解析库,自称性能天下第一、API简单易用、也是目前主流的JSON解析库,但安全风险高 |
| fastjson2 | fastjson2是fastjson的升级版,同样号称“性能顶破天,支撑JSON解析下一个十年”的知名JSON解析库 |
| dsl-json | 性能最强但用户量极小(应该是因为DSL原因)的JSON解析库 |
| org.json | 上一个十年(2010年左右)最为流行的JSON解析库 |
| johnzon | TomEE中的JWS-RS默认使用的JSON解析库,性能非常差 |
0x01 注释符
部分JSON解析库支持在JSON中插入注释符,注释符中的任何字符不会被解析。
- gson支持
/**/(多行)、//(单行)、#(单行)这三类注释符; - fastjson支持除
#以外的注释符; - fastjson2只支持
//注释符;
| payload | gson | jackson | fastjson | fastjson2 | dsl-json | org.json | johnzon |
|---|---|---|---|---|---|---|---|
| /**/(多行) | √ | √ | |||||
| //(单行) | √ | √ | √ | ||||
| #(单行) | √ |
0x02 首个Unicode空白符
首个Unicode空白字符指的是{}、[]、注释符之前的可被JSON库解析的有效字符,这个特性可用来绕过某些解析JSON请求时不看Content-Type,只看输入流是否是以{或者[开始的字符(针对一些特殊的字符trim也没用)的RASP或者WAF,除了使用特殊字符以外,某些场景下其实还可以使用注释符来代替这些特殊的Unicode字符。
- 统计表中不包含正常的用于表示空白符的
\t、\n、\r; - fastjson支持
0x00; - fastjson和org.json支持
>0,<=32的ASCII字符; - dsl-json支持较多大于127的Unicode字符;
表 - 首个Unicode字符解析:
| Unicode | gson | jackson | fastjson | fastjson2 | dsl-json | org.json | johnzon |
|---|---|---|---|---|---|---|---|
| 0 | √ | ||||||
| 1-7 | √ | √ | |||||
| 8 | √ | √ | √ | ||||
| 11 | √ | √ | √ | ||||
| 12 | √ | √ | √ | √ | |||
| 14-31 | √ | √ | |||||
| 127 | √ | ||||||
| 5760 | √ | ||||||
| 8192 - 8202 | √ | ||||||
| 8232 - 8233 | √ | ||||||
| 8239 | √ | ||||||
| 8287 | √ | ||||||
| 12288 | √ | ||||||
| 65279 | √ | √ | √ | ||||
| 65534 | √ |
从解析情况来看,有一些大于127的Unicode字符也能被某些JSON解析库解析,这是如何做到的呢?
2.1 fastjson2
fastjson2支持的空白符比较常规,com.alibaba.fastjson2.JSONReader类中的SPACE代码中定义了允许换行的特殊字符:
static final long SPACE = (1L << ' ') | (1L << '\n') | (1L << '\r') | (1L << '\f') | (1L << '\t') | (1L << '\b');
除此之外,还有\uFFFE(编码为65534)和\uFEFF(编码为65279),这两个字符可以当做空白符(这两个特殊字符是用来表示UTF16中的BOM,byte order mark 字节序标记),如下图:
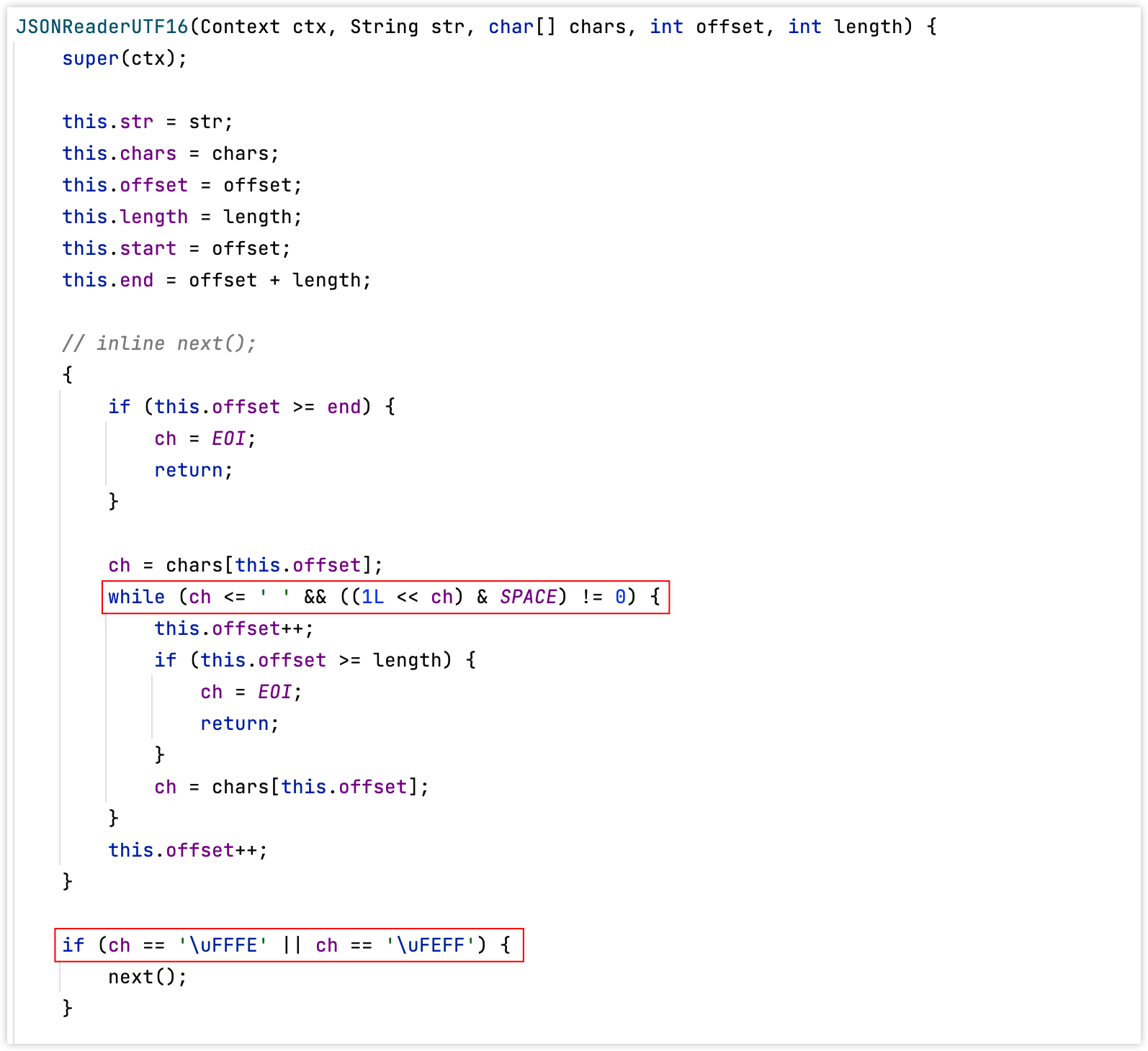
在UTF-16中,字节顺序标记被放置为文件或文字符串流的第一个字符,以标示在此文件或文字符串流中,以所有十六比特为单位的字码的端序(字节顺序)。如果试图用错误的字节顺序来读取这个流,字节将被调换,从而产生字符U+FFFE,这个字符被Unicode定义为“非字符”,不应该出现在文本中。例如,值为U+FFFE的码位被保证将不会被指定成一个统一码字符。这意味着0xFF、0xFE将只能被解释成小端序中的U+FEFF(因为不可能是大端序中的U+FFFE)。
表 - 不同编码的字节顺序标记
| 编码 | 十六进制 | 十进制 | byte[] |
|---|---|---|---|
| UTF-8 | EF BB BF | 239 187 191 | -17 -69 -65 |
| UTF-16 BE | FE FF | 254 255 | -2 -1 |
| UTF-16 LE | FF FE | 255 254 | -1 -2 |
| UTF-32 BE | 00 00 FE FF | 0 0 254 255 | 0 0 -2 -1 |
| UTF-32 LE | FF FE 00 00 | 255 254 0 0 | -1 -2 0 0 |
| UTF-7 | 2B 2F 76 | 43 47 118 | 43 47 118 |
| UTF-1 | F7 64 4C | 247 100 76 | -9 100 76 |
| UTF-EBCDIC | DD 73 66 73 | 221 115 102 115 | -35 115 102 115 |
| SCSU | 0E FE FF | 14 254 255 | 14 -2 -1 |
| BOCU-1 | FB EE 28 | 251 238 40 | -5 -18 40 |
| GB18030 | 84 31 95 33 | 132 49 149 51 | -124 49 -107 51 |
因此gson/fastjson/fastjson2/支持\uFEFF也就显得比较合理了,但实际情况并不会根据BOM解析对应的编码。
2.1 dsl-json
dsl-json使用的是boolean[256]来存储所有空白符,对应的是byte(-128到127),last + 128是为了去除符号,也就是说只要byte位不在空白符所对应的取值区间,那么是不会有任何问题的。
图 - dsl-json空白符取值范围:
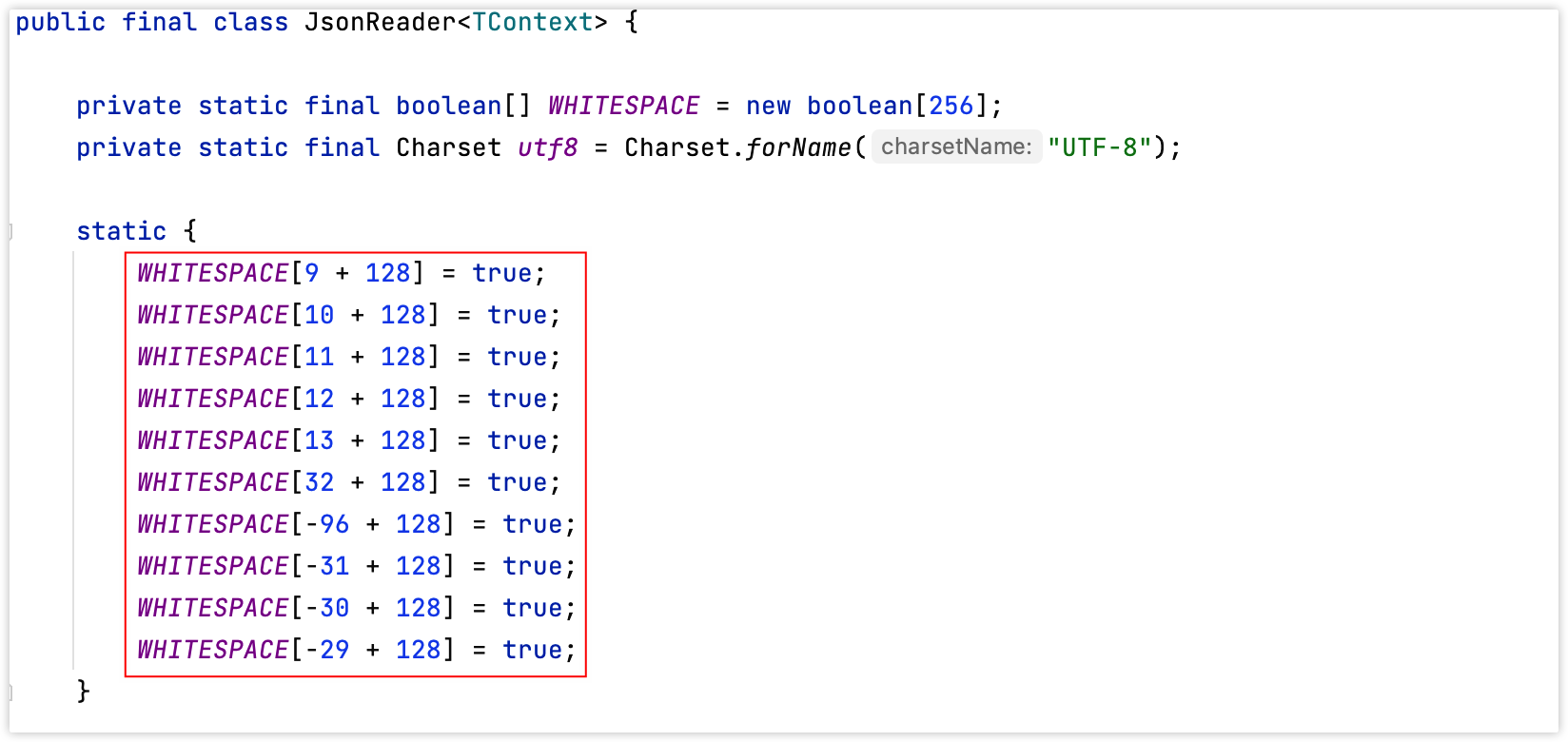
由上图可知,dsl-json只是约束了部分的byte字符为空白符,看似并不存在任何问题,但是JSON必须是一个字符串,而字符串本质上是由char组成的,而char又是由byte数组编码而来的,而一个UTF-8字符是由多个字节组成的,因此当我们使用一个大于127的Unicode字符时会由多个字节所表示。
比如:Unicode字符က(char,对应的编码为4096),က这个字符转换成byte后变成了3位的byte数组,即:-31 -128 -128,而dsl-json解析时会将byte位作为最小单元而不是char(char),而-31这个字节正好符合了第一个if判断,如下图:
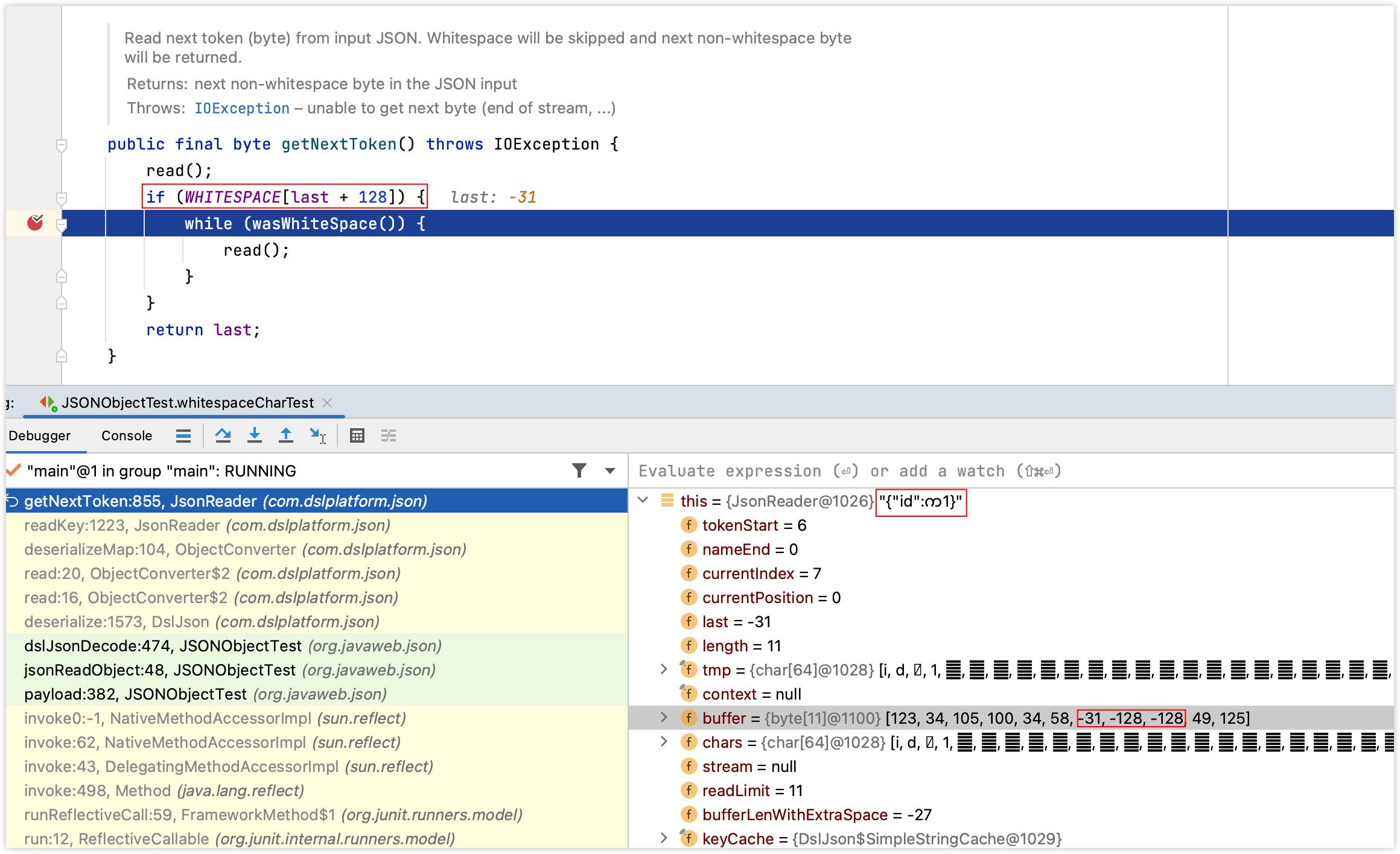
显然,wasWhiteSpace这个方法的逻辑关系到是否会将က处理,因为目前只是处理了-31,后面的-128 -128因此需要进入该方法进一步的分析,如下图:

分析-31的处理逻辑后得知,后面的两个byte位必须是-102和-128(也就是编码为5760的字符)才能被当做是空白符,而-31 -128 -128并不符合这个条件,因此က并不能当做空白符使用。
不过这里可以用其他的字符代替,例如:编码为8192的Unicode字符(byte为-30 -128 -128),完美符合上图的case -30的逻辑判断,因此dsl-json中的字符编码8192支持当做空白符解析,表格中列举的其他的字符同理。
0x03 引号
在标准的JSON中key、value(非整形)都需要使用使用引号引起来,在Java中默认使用"(双引号)来包裹key/value,但是存在一些特殊的库支持'(单引号)甚至是不使用任何单双引号来处理key和字符类型的value。
- fastjson、gson、org.json支持
'、"、无引号; - fastjson支持单双引号,无引号混用,但是fastjson不支持key、value都是引号;
- 支持单双引号的库都支持单双引号混用;
| payload | gson | jackson | fastjson | fastjson2 | dsl-json | org.json | johnzon |
|---|---|---|---|---|---|---|---|
| {'id': "1"} | √ | √ | √ | √ | |||
| {id: "1"} | √ | √ | √ | ||||
| {id: 2b} | √ | √ |
0x04 超大JSON
超大JSON指的是压测JSON解析上限,在很多时候传入一个较大的JSON字符串就可以轻易的绕过RASP和WAF的防御,其本质一方面是性能考虑,另一方面很有可能是RASP或者WAF所使用的JSON解析库根本就不支持大的JSON字符串解析。
- fastjson压测500M以上暂未发现有内存上限;
- 最小的是dsl-json,仅128M;
注:1M = 1024 * 1024
| 名称 | 范围 |
|---|---|
| gson | <512M |
| jackson | <484M |
| fastjson | ∞ |
| fastjson2 | ∞ |
| dsl-json | <=128M |
| org.json | ∞(不稳定) |
| johnzon | <494M |
0x05 进制转换
目前测试的所有JSON库都支持Unicode编码,fastjson支持\x(十六进制)和\(八进制)。
- 只有fastjson和fastjson2支持
十六进制(\x); - 只有fastjson和fastjson2支持
八进制(\1)字符解析,0-7范围内; - fastjson2在解析
Unicode(\u)和十六进制(\x)字符时会将不认识的字符时不会报错,会转换成其缓存数组中的\u0000; - jackson和fastjson在转换Unicode时都是计算出来的Unicode编码,因此很容易出现解析错误,例如:jackson解析
\u൦൦31时结果为Q; - 使用Integer.parseInt来实现进制转换的解析库都会出现Unicode字符int只碰撞问题,例如:
႐、꘠转换成int后都可以表示十进制的数字0,因此\u႐꘠31和\u0031解析后都是十进制的数字1。
表 - Unicode/Hex解析表
| payload | gson | jackson | fastjson | fastjson2 | dsl-json | org.json | johnzon |
|---|---|---|---|---|---|---|---|
| \u 003 | 0x03 | ||||||
| \u^?31 | 1 | ||||||
| \u႐꘠31 | 1 | ||||||
| \u൦൦31 | Q | 1 | 1 | ||||
| \x\tA | \n | ||||||
| \x31 | 1 | 1 | |||||
| \7 | 0x07 | 0x07 |
Fastjson1
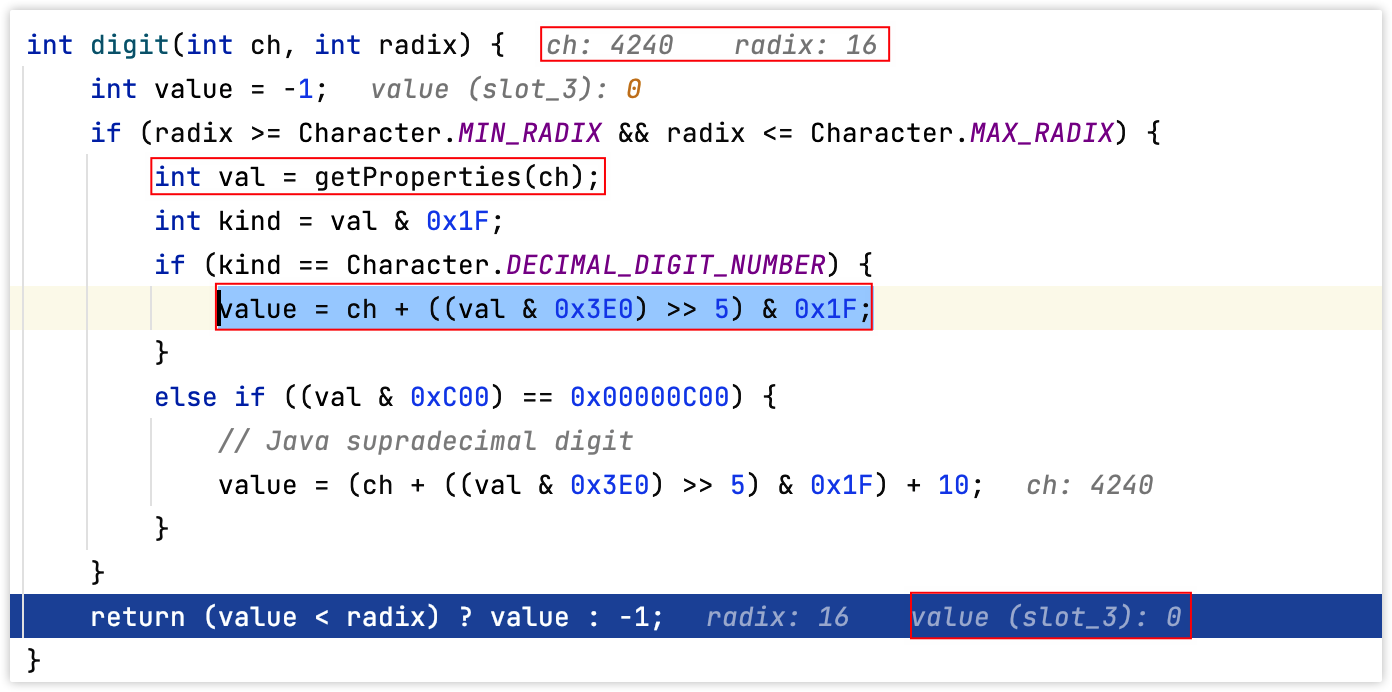
fastjson1解析Unicode时使用的是Integer#parseInt,而有很多Unicode字符转换成数字后会有重复的情况,比如Unicode编码႐(4240)转换成int后的值为0,也就是说႐=0。
Unicode
fastjson1支持Unicode字符解析,使用的是将Unicode字符转换成整型,然后将整型转换成char,例如:\u႐꘠31去掉\u后再按位读取就成了:႐、꘠、3、1,然后再使用Integer#parseInt将႐꘠31以16进制的方式转换成int后得到49,最后将49转换成char就变成了ASCII编码的1。
图 - com.alibaba.fastjson.parser.JSONLexerBase#scanString Unicode解码\u႐꘠31

႐、꘠对应的4240、42528经过Integer#parseInt转换后都是0,具体的转换逻辑在java.lang.CharacterData00#digit,如下图:
3、1对应的51、49会使用java.lang.CharacterDataLatin1#digit处理。
按照Unicode解析逻辑,那么不难看出Hex也应当是相同的解析方法,那么为什么Hex解析没有这个问题呢?原因在于Hex解析的时候强制限制了编码范围,仅允许:48-57(0-9)、65-70(A-F)、97-102(a-f)范围内的编码。
com.alibaba.fastjson.parser.JSONLexerBase#scanString() 代码片段:
case 'x':
char x1 = next();
char x2 = next();
boolean hex1 = (x1 >= '0' && x1 <= '9')
|| (x1 >= 'a' && x1 <= 'f')
|| (x1 >= 'A' && x1 <= 'F');
boolean hex2 = (x2 >= '0' && x2 <= '9')
|| (x2 >= 'a' && x2 <= 'f')
|| (x2 >= 'A' && x2 <= 'F');
if (!hex1 || !hex2) {
throw new JSONException("invalid escape character \\x" + x1 + x2);
}
char x_char = (char) (digits[x1] * 16 + digits[x2]);
putChar(x_char);
break;
Fastjson2
fastjson2解析Unicode字符和Hex时遇到无法识别的字符就当0x00处理,因此能够解析其他JSON库无法解析的编码。
Unicode
fastjson2解析Unicode时候会忽略错误的编码,例如:\u^?31,^?根本就不是正确的Unicode编码,fastjson2无法识别,就直接当成了\u00了,所以\u^?31就成了\u0031即十进制的1。
com.alibaba.fastjson2.JSONReaderUTF16#readString 代码片段:
// 编码\u0000字符,连续读取4个字符
case 'u': {
char c1 = chars[offset++];
char c2 = chars[offset++];
char c3 = chars[offset++];
char c4 = chars[offset++];
ch = char4(c1, c2, c3, c4);
break;
}
com.alibaba.fastjson2.JSONReader#char4 代码片段:
static final int[] DIGITS2 = new int[]{
+0, +0, +0, +0, +0, +0, +0, +0, +0, +0, +0, +0, +0, +0, +0, +0,
+0, +0, +0, +0, +0, +0, +0, +0, +0, +0, +0, +0, +0, +0, +0, +0,
+0, +0, +0, +0, +0, +0, +0, +0, +0, +0, +0, +0, +0, +0, +0, +0,
+0, +1, +2, +3, +4, +5, +6, +7, +8, +9, +0, +0, +0, +0, +0, +0,
+0, 10, 11, 12, 13, 14, 15, +0, +0, +0, +0, +0, +0, +0, +0, +0,
+0, +0, +0, +0, +0, +0, +0, +0, +0, +0, +0, +0, +0, +0, +0, +0,
+0, 10, 11, 12, 13, 14, 15
};
static char char4(int c1, int c2, int c3, int c4) {
return (char) (DIGITS2[c1] * 0x1000
+ DIGITS2[c2] * 0x100
+ DIGITS2[c3] * 0x10
+ DIGITS2[c4]);
}
DIGITS2是编码表,使用数组表示0-103的所有ASCII字符,有效的Unicode字符必须小于等于102(97-102的ASCII码为a-f),48-57对应的是ASCII编码后的数字(0-9),65-70对应的是ASCII编码后的大写字母(A-F),65-70等价于97-102,因为Hex是不区分大小写的,所以这个编码表才会如此的怪异。
char4方法是用来计算4位Unicode字符编码的,4位字符代表的是\u后的字符,例如\u0031,经过切割后就变成了0、0、3、1这四位字符了。每一位都必须对应DIGITS2表中的字符,只有有效字符:0-9A-Fa-f才会取到对应的值,否则全部补0。按高低位分别乘以4096(0x1000)、256(0x100)、16(0x10)、1(0x01),最后算出来Unicode字符的int值,并转换成char。需要注意的是取值范围仅0-65535,15*4096+15*256+15*16+15=65535。
以\u^?31为例,我们可以算一下经过fastjson2转码后的Unicode字符是什么,经过切割后得到:^、?、3、1四位字符等价于ASCII字符:94、63、51、49,逐个对应DIGITS2表得到0(94)、0(63)、3(51)、1(49)这四位数字,然后按位计算:0 * 4096 + 0 * 256 + 3 * 16 + 1 * 1 = 49,最后将49(ASCII码)转换成char即字符1。
利用这个编码表和算法,可以计算出几乎所有我们想要的字符,重点是其他的JSON解析库还都无法识别!
Hex
Hex解析也是同样的道理,遇到无法识别的字符都当0x00处理,例如:\x\tA中的\t不是合法的Hex字符,因此会被fastjson2当做\x0处理,所以\x\tA最终会当做\x0A解析,因此最终解析后的结果就成了\n了。
com.alibaba.fastjson2.JSONReaderUTF16#readString 代码片段:
// 编码\x00字符,连续读取2个字符
case 'x': {
char c1 = this.chars[++offset];
char c2 = this.chars[++offset];
c = char2(c1, c2);
break;
}
com.alibaba.fastjson2.JSONReader#char2
static char char2(int c1, int c2) {
return (char) (DIGITS2[c1] * 0x10 + DIGITS2[c2]);
}
Hex编码计算方式和Unicode是一样的,这里不在赘述。
Octal
fastjson2支持部分八进制字符(0-7),例如八进制:\43对应的ASCII字符是#,但是fastjson2并不支持,因此fastjson2支持的并不是真正意义上的八进制。
com.alibaba.fastjson2.JSONReader#char1
static char char1(int c) {
switch (c) {
case '0':
return '\0';
case '1':
return '\1';
case '2':
return '\2';
case '3':
return '\3';
case '4':
return '\4';
case '5':
return '\5';
case '6':
return '\6';
case '7':
return '\7';
case 'b': // 8
return '\b';
case 't': // 9
return '\t';
case 'n': // 10
return '\n';
case 'v': // 11
return '\u000B';
case 'f': // 12
case 'F':
return '\f';
case 'r': // 13
return '\r';
case '"': // 34
case '\'': // 39
case '/': // 47
case '.': // 47
case '\\': // 92
case '#':
case '&':
case '[':
case ']':
case '@':
case '(':
case ')':
return (char) c;
default:
throw new JSONException("unclosed.str.lit " + (char) c);
}
}
分析上面的代码可知,fastjson还支持转义:"、'、/、.、\、#、&、[、]、@、(、),例如:\@type,转义后会变为@type。
Jackson
Jackson只支持Unicode编码,Jackson处理Unicode的方式类似于Fastjson2,也是使用的数组来处理0-255的字符,大于255的会强制转换成0-255之间的数。
以{"id\":"\u൦൦31"}为例,Jackson解析后id值为Q(65329),而fastjson1和org.json解析出来的都是1,\u൦൦31中的൦൦并不是数字0而是Unicode字符൦(3430),下面将详细分析为什么会解析成Q(65329)。
com.fasterxml.jackson.core.json.ReaderBasedJsonParser#_decodeEscaped 代码片段:
// Ok, a hex escape. Need 4 characters
int value = 0;
for (int i = 0; i < 4; ++i) {
if (_inputPtr >= _inputEnd) {
if (!_loadMore()) {
_reportInvalidEOF(" in character escape sequence", JsonToken.VALUE_STRING);
}
}
int ch = (int) _inputBuffer[_inputPtr++];
int digit = CharTypes.charToHex(ch);
if (digit < 0) {
_reportUnexpectedChar(ch, "expected a hex-digit for character escape sequence");
}
value = (value << 4) | digit;
}
return (char) value;
Jackson会将൦൦31逐个字符的使用com.fasterxml.jackson.core.io.CharTypes#charToHex解析,最后再通过位运算将四个字符对应的int值换算成一个int值,接下来分析൦(3430)是如何解析的。
com.fasterxml.jackson.core.io.CharTypes#charToHex 代码片段:
int[] sHexValues = [-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, -1, -1, -1, -1, -1, -1, -1, 10, 11, 12, 13, 14, 15, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 10, 11, 12, 13, 14, 15, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1];
public static int charToHex(int ch) {
// 08-Nov-2019, tatu: As per [core#540] and [core#578], changed to
// force masking here so caller need not do that.
return sHexValues[ch & 0xFF];
}
通过上面的代码注释可知,Jackson曾经出现过下标越界问题:Array index out of bounds in hex lookup #578和UTF8StreamJsonParser: fix byte to int conversion for malformed escapes #540,解决方式就是将int值& 0xFF,这样就能得到一个无符号的0-255之间的数了。
将൦(3430)的3430转换成二进制:110101100110,然后将0xFF的255转换成二进制:000011111111,使用&,按位运算:

得到结果:000001100110,转换成十进制:102,然后在sHexValues中查看对应的值:15,然后再通过(value << 4) | digit为value赋值,因为value此时为0,因此0 <<4还是0,所以此时的value值为0 | 15也就是15。
以此类推,第二个字符也是൦(3430),charToHex后依旧是15,不过不同的是此时的value值已经是15了,因此15 <<4为240,第二位字符运算后value的值就成了240 | 15也就是255。
第三个字符3(51),charToHex的值是3,255 <<4 =4080,4080 | 3也就是4083,第四个字符1(49),charToHex的值是1,4083 <<4 =65328,65328 | 1也就是65329,最后再将65329转换成char后就变成了Q(65329)。
因此\u൦൦31经过charToHex和位运算后得到的最终字符是Q(65329),而同样的Unicode字符由于Fastjson1使用的是Integer#parseInt得到的值却是ASCII编码的49,即数字1。
此时便可看出两种不同的算法得出来的值的差异,合理的利用解析不一致的特性即可绕过RASP和WAF的检测。因为在使用Fastjson1的RASP来说,他取到的字符是1(Fastjson2甚至无法解析),而Spring MVC自带的Jackson解析出来的却是Q(65329),带入RASP的零规则检测将无从得知Q(65329)从何而来,因此即便是请求参数中带入了明显的恶意payload也不会当做恶意攻击。
0x06 基础类型
基础类型指的是java中的八大基础类型:boolean、byte、short、int、long、char、float、double,除此之外这里还引用了有符号数和科学计数法。
- GSON和JSON因为支持识别无引号的value,因此会解析特殊的基础类型为字符串;
- 除了fastjson都不支持解析
1B、1S、1L这类基础类型; - fastjson/fastjson2/org.json支持
1.0D、1.0F; - fastjson支持的基础类型最多,不管是合法的还是不合法的几乎都支持,例如:
01、.0、+.0、+-0.1; - true支能小写,大写后就成了字符串
TRUE
| payload | gson | jackson | fastjson | fastjson2 | dsl-json | org.json | johnzon |
|---|---|---|---|---|---|---|---|
| 1B | "1B" | 1 | 1 | "1B" | |||
| 1S | "1S" | 1 | 1 | "1S" | |||
| 1L | "1L" | 1 | 1 | "1L" | |||
| 1.0F | "1.0F" | 1.0 | 1.0 | 1.0 | |||
| 1.0D | "1.0D" | 1.0 | 1.0 | 1.0 | |||
| +1 | "+1" | 1 | 1 | 1 | "+1" | ||
| 01 | "01" | 1 | 1 | "01" | |||
| .0 | ".0" | 0.0 | ".0" | ||||
| -.0 | "-.0" | 0.0 | 0.0 | -0.0 | |||
| +.0 | "+.0" | 0.0 | 0.0 | 0.0 | "+.0" | ||
| +-0.1 | "+-0.1" | -0.1 | "+-0.1" | ||||
| TRUE | "TRUE" | "TRUE" |
0x07 字段解析
字段解析指的是{}、[]中的key/value解析支持情况,本节和空。
- fastjson允许
{后有,和}之前有,,fastjson2支允许value后面有多余的,; - gson/org.json允许value都不带引号,gson key/value首字母都允许不带引号;
- org.json支持不带引号的字符串中出现空白符;
| payload | gson | jackson | fastjson | fastjson2 | dsl-json | org.json | johnzon |
|---|---|---|---|---|---|---|---|
| {,"id": 1,} | √ | ||||||
| {"id": 1,} | √ | √ | √ | ||||
| {"id": 测试'} | √ | √ | |||||
| {"id": 测试'"} | √ | ||||||
| {id'": 测试'"} | √ | ||||||
| {"id": or 1} | √ |
0x08 空对象
空对象指的是key/value为空,当JSON解析时遇到null/NULL时只有部分的JSON库能够支持(默认配置)。
- gson、fastjson、org.json支持解析null;
- fastjson支持NaN(js中的Not a number);
| payload | gson | jackson | fastjson | fastjson2 | dsl-json | org.json | johnzon |
|---|---|---|---|---|---|---|---|
| {"id": NULL} | id=null | id=null | id=null | ||||
| {"id": NaN} | id="NaN" | id=null | id="NaN" | ||||
| {null: null} | "null"=null | "null"=null | "null"="null" |
0x09 字符转义
常规的转义字符有10个:\b、\t、\n、\f、\r、"、/、\、u、',fastjson/fastjson2有一些自己定义的转义字符:\v(等价于\t)、\F(等价于\f)、\x,fastjson2还支持转义:.、-、+、*、/、>、<、=、@、:,例如:\@,转义后会变为@。
| payload | gson | jackson | fastjson | fastjson2 | dsl-json | org.json | johnzon |
|---|---|---|---|---|---|---|---|
| {"id": "\v"} | √ | √ | |||||
| {"id": "\F"} | √ | √ | |||||
| {"id": "\7"} | √ | √ | |||||
| {"id": "\@"} | √ |
图 - fastjson2转义字符解析:

0x10 空白符
空白符指的是JSON中的key/value/分隔符之间允许存在的无意义字符,标准的空白符:0x09(\t)、0x10(\n)、0x32(空格),除此之外不同的JSON库还支持一些特别的空白符。
- gson能正常解析的空白符只有
9/10/13/32; - gson几乎支持解析所有的key/value首个字符的Unicode(除:
"、/、#、/、'、/、:、;、=、[、\、]、{之外); - johnzon不支持解析超过10w个换行符;
- jackson、dsl-json、org.json最末尾的字符可以是任何Unicode字符;
- dsl-json支持一些大于127的特殊的Unicode字符作为空白符;
- org.json解析多个key/value时,最后一个value后面支持多个
,,fastjson/fastjson2解析value时支持多个,;
| payload | gson | jackson | fastjson | fastjson2 | dsl-json | org.json | johnzon |
|---|---|---|---|---|---|---|---|
| 1000000个\n | × | ||||||
| {空白符"id": "1", "id2": "2"} | 9/10/32 | 9/10/32 | 8-10/12/32/44 | 0/8-10/12/32 | 9-12/32/125/5760/8192-8233/8239/8287/12288 | 1-12/14-32/125 | 9/10/32 |
| {"id"空白符: "1", "id2": "2"} | 9/10/32 | 9/10/32 | 8-10/12/32 | 8-10/12/32 | 9-12/32/5760/8192-8202/8232-8233/8239/8287/12288 | 1-12/14-32 | 9/10/32 |
| {"id": "1", 空白符"id2": "2"} | 9/10/32 | 9/10/32 | 8-10/12/32/44 | 8-10/12/32 | 9-12/32/5760/8192-8202/8232-8233/8239/8287/12288 | 1-12/14-32/125 | 9/10/32 |
| {"id": "1", "id2": "2"空白符} | 9/10/32 | 9/10/32/125 | 8-10/12/32/44 | 8-10/12/32/44 | 9-12/32/125/5760/8192-8202/8232-8233/8239/8287/12288 | 1-12/14-32/44/59/125 | 9/10/32 |
| {"id": "1", "id2": "2"}空白符 | 9/10/13/32 | 无限制 | 0-32/127 | 0/8-10/12-13/26/32/44 | 无限制 | 无限制 | 0/9/10/13/32 |
| {"id": \u00001} | \u00001 | 1 | 1 | ||||
| {"id": \u00008} | "\b1" | 1 | 1 | 1 |
0x11 分割符
JSON key/value默认的分割字符是:,(逗号),但是gson、jackson、dsl-json、org.json支持除,以外的;(分号)和}(大括号)。
| payload | gson | jackson | fastjson | fastjson2 | dsl-json | org.json | johnzon |
|---|---|---|---|---|---|---|---|
| {"id": 1;"id2": 2} | √ | √ | |||||
| {"id": 1}"id2": 2} | id=1 | id=1 | id=1 |
0x12 错误解析
- fastjson1在将JSON反序列化成Java对象时没有正确的解析String,解析类方法: com.alibaba.fastjson.parser.JSONLexerBase#scanFieldString,该方法截取了
"之前的值,忽略了多余的字符串; - gson支持解析无引号的JSON,因此如果特殊字符出现在value的第一个字符时可以正常解析,例如:
{)"id":"1", "name": "1"},解析结果:)"id"=1、name=1;
| payload | gson | jackson | fastjson | fastjson2 | dsl-json | org.json | johnzon |
|---|---|---|---|---|---|---|---|
| {"id":"1"(} | id=1 | ||||||
| {)"id":"1", "name": "1"} | name=1 |
参考:GlassyAmadeus/FuzzProject - JsonFuzz.java
0x13 JSON库解析代码
附本文所列举的JSON库解析字符串或转unicode的核心代码。
Gson
com.google.gson.stream.JsonReader#readEscapeCharacter
private char readEscapeCharacter() throws IOException {
if (pos == limit && !fillBuffer(1)) {
throw syntaxError("Unterminated escape sequence");
}
char escaped = buffer[pos++];
switch (escaped) {
case 'u':
if (pos + 4 > limit && !fillBuffer(4)) {
throw syntaxError("Unterminated escape sequence");
}
// Equivalent to Integer.parseInt(stringPool.get(buffer, pos, 4), 16);
char result = 0;
for (int i = pos, end = i + 4; i < end; i++) {
char c = buffer[i];
result <<= 4;
if (c >= '0' && c <= '9') {
result += (c - '0');
} else if (c >= 'a' && c <= 'f') {
result += (c - 'a' + 10);
} else if (c >= 'A' && c <= 'F') {
result += (c - 'A' + 10);
} else {
throw new NumberFormatException("\\u" + new String(buffer, pos, 4));
}
}
pos += 4;
return result;
case 't':
return '\t';
case 'b':
return '\b';
case 'n':
return '\n';
case 'r':
return '\r';
case 'f':
return '\f';
case '\n':
lineNumber++;
lineStart = pos;
// fall-through
case '\'':
case '"':
case '\\':
case '/':
return escaped;
default:
// throw error when none of the above cases are matched
throw syntaxError("Invalid escape sequence");
}
}
Jackson
com.fasterxml.jackson.core.json.ReaderBasedJsonParser#_decodeEscaped
protected char _decodeEscaped() throws IOException {
if (_inputPtr >= _inputEnd) {
if (!_loadMore()) {
_reportInvalidEOF(" in character escape sequence", JsonToken.VALUE_STRING);
}
}
char c = _inputBuffer[_inputPtr++];
switch ((int) c) {
// First, ones that are mapped
case 'b':
return '\b';
case 't':
return '\t';
case 'n':
return '\n';
case 'f':
return '\f';
case 'r':
return '\r';
// And these are to be returned as they are
case '"':
case '/':
case '\\':
return c;
case 'u': // and finally hex-escaped
break;
default:
return _handleUnrecognizedCharacterEscape(c);
}
// Ok, a hex escape. Need 4 characters
int value = 0;
for (int i = 0; i < 4; ++i) {
if (_inputPtr >= _inputEnd) {
if (!_loadMore()) {
_reportInvalidEOF(" in character escape sequence", JsonToken.VALUE_STRING);
}
}
int ch = (int) _inputBuffer[_inputPtr++];
int digit = CharTypes.charToHex(ch);
if (digit < 0) {
_reportUnexpectedChar(ch, "expected a hex-digit for character escape sequence");
}
value = (value << 4) | digit;
}
return (char) value;
}
Fastjson1
com.alibaba.fastjson.parser.JSONLexerBase#scanString()
public final void scanString() {
np = bp;
hasSpecial = false;
char ch;
for (;;) {
ch = next();
if (ch == '\"') {
break;
}
if (ch == EOI) {
if (!isEOF()) {
putChar((char) EOI);
continue;
}
throw new JSONException("unclosed string : " + ch);
}
if (ch == '\\') {
if (!hasSpecial) {
hasSpecial = true;
if (sp >= sbuf.length) {
int newCapcity = sbuf.length * 2;
if (sp > newCapcity) {
newCapcity = sp;
}
char[] newsbuf = new char[newCapcity];
System.arraycopy(sbuf, 0, newsbuf, 0, sbuf.length);
sbuf = newsbuf;
}
copyTo(np + 1, sp, sbuf);
// text.getChars(np + 1, np + 1 + sp, sbuf, 0);
// System.arraycopy(buf, np + 1, sbuf, 0, sp);
}
ch = next();
switch (ch) {
case '0':
putChar('\0');
break;
case '1':
putChar('\1');
break;
case '2':
putChar('\2');
break;
case '3':
putChar('\3');
break;
case '4':
putChar('\4');
break;
case '5':
putChar('\5');
break;
case '6':
putChar('\6');
break;
case '7':
putChar('\7');
break;
case 'b': // 8
putChar('\b');
break;
case 't': // 9
putChar('\t');
break;
case 'n': // 10
putChar('\n');
break;
case 'v': // 11
putChar('\u000B');
break;
case 'f': // 12
case 'F':
putChar('\f');
break;
case 'r': // 13
putChar('\r');
break;
case '"': // 34
putChar('"');
break;
case '\'': // 39
putChar('\'');
break;
case '/': // 47
putChar('/');
break;
case '\\': // 92
putChar('\\');
break;
case 'x':
char x1 = next();
char x2 = next();
boolean hex1 = (x1 >= '0' && x1 <= '9')
|| (x1 >= 'a' && x1 <= 'f')
|| (x1 >= 'A' && x1 <= 'F');
boolean hex2 = (x2 >= '0' && x2 <= '9')
|| (x2 >= 'a' && x2 <= 'f')
|| (x2 >= 'A' && x2 <= 'F');
if (!hex1 || !hex2) {
throw new JSONException("invalid escape character \\x" + x1 + x2);
}
char x_char = (char) (digits[x1] * 16 + digits[x2]);
putChar(x_char);
break;
case 'u':
char u1 = next();
char u2 = next();
char u3 = next();
char u4 = next();
int val = Integer.parseInt(new String(new char[] { u1, u2, u3, u4 }), 16);
putChar((char) val);
break;
default:
this.ch = ch;
throw new JSONException("unclosed string : " + ch);
}
continue;
}
if (!hasSpecial) {
sp++;
continue;
}
if (sp == sbuf.length) {
putChar(ch);
} else {
sbuf[sp++] = ch;
}
}
token = JSONToken.LITERAL_STRING;
this.ch = next();
}
Fastjson2
com.alibaba.fastjson2.JSONReaderUTF16#readString
public String readString() {
if (ch == '"' || ch == '\'') {
final char quote = ch;
int offset = this.offset;
int start = offset;
int valueLength;
boolean valueEscape = false;
_for:
{
int i = 0;
char c0 = 0, c1 = 0, c2 = 0, c3 = 0;
// vector optimize
boolean quoted = false;
int upperBound = offset + ((end - offset) & ~3);
while (offset < upperBound) {
c0 = chars[offset];
c1 = chars[offset + 1];
c2 = chars[offset + 2];
c3 = chars[offset + 3];
if (c0 == '\\' || c1 == '\\' || c2 == '\\' || c3 == '\\') {
break;
}
if (c0 == quote || c1 == quote || c2 == quote || c3 == quote) {
quoted = true;
break;
}
offset += 4;
i += 4;
}
if (quoted) {
if (c0 == quote) {
// skip
} else if (c1 == quote) {
offset++;
i++;
} else if (c2 == quote) {
offset += 2;
i += 2;
} else if (c3 == quote) {
offset += 3;
i += 3;
}
valueLength = i;
} else {
for (; ; ++i) {
if (offset >= end) {
throw new JSONException(info("invalid escape character EOI"));
}
char c = chars[offset];
if (c == '\\') {
valueEscape = true;
c = chars[++offset];
switch (c) {
case 'u': {
offset += 4;
break;
}
case 'x': {
offset += 2;
break;
}
default:
// skip
break;
}
offset++;
continue;
}
if (c == quote) {
valueLength = i;
break _for;
}
offset++;
}
}
}
String str;
if (valueEscape) {
char[] chars = new char[valueLength];
offset = start;
for (int i = 0; ; ++i) {
char c = this.chars[offset];
if (c == '\\') {
c = this.chars[++offset];
switch (c) {
case 'u': {
char c1 = this.chars[++offset];
char c2 = this.chars[++offset];
char c3 = this.chars[++offset];
char c4 = this.chars[++offset];
c = char4(c1, c2, c3, c4);
break;
}
case 'x': {
char c1 = this.chars[++offset];
char c2 = this.chars[++offset];
c = char2(c1, c2);
break;
}
case '\\':
case '"':
break;
default:
c = char1(c);
break;
}
} else if (c == quote) {
break;
}
chars[i] = c;
offset++;
}
if (STRING_CREATOR_JDK8 != null) {
str = STRING_CREATOR_JDK8.apply(chars, Boolean.TRUE);
} else {
str = new String(chars);
}
} else {
if (this.str != null && JVM_VERSION > 8) {
str = this.str.substring(this.offset, offset);
} else {
str = new String(chars, this.offset, offset - this.offset);
}
}
if ((context.features & Feature.TrimString.mask) != 0) {
str = str.trim();
}
if (offset + 1 == end) {
this.offset = end;
this.ch = EOI;
comma = false;
return str;
}
int b = chars[++offset];
while (b <= ' ' && ((1L << b) & SPACE) != 0) {
b = chars[++offset];
}
if (comma = (b == ',')) {
this.offset = offset + 1;
// inline next
ch = this.offset == end ? EOI : chars[this.offset++];
while (ch <= ' ' && ((1L << ch) & SPACE) != 0) {
if (this.offset >= end) {
ch = EOI;
} else {
ch = chars[this.offset++];
}
}
} else {
this.offset = offset + 1;
this.ch = (char) b;
}
return str;
}
switch (ch) {
case '[':
return toString(
readArray());
case '{':
return toString(
readObject());
case '-':
case '+':
case '0':
case '1':
case '2':
case '3':
case '4':
case '5':
case '6':
case '7':
case '8':
case '9':
readNumber0();
Number number = getNumber();
return number.toString();
case 't':
case 'f':
boolValue = readBoolValue();
return boolValue ? "true" : "false";
case 'n': {
readNull();
return null;
}
default:
throw new JSONException("TODO : " + ch);
}
}
DSL-Json
com.dslplatform.json.JsonReader#parseString
final int parseString() throws IOException {
final int startIndex = currentIndex;
if (last != '"') throw newParseError("Expecting '\"' for string start");
else if (currentIndex == length) throw newParseErrorAt("Premature end of JSON string", 0);
byte bb;
int ci = currentIndex;
char[] _tmp = chars;
final int remaining = length - currentIndex;
int _tmpLen = _tmp.length < remaining ? _tmp.length : remaining;
int i = 0;
while (i < _tmpLen) {
bb = buffer[ci++];
if (bb == '"') {
currentIndex = ci;
return i;
}
// If we encounter a backslash, which is a beginning of an escape sequence
// or a high bit was set - indicating an UTF-8 encoded multibyte character,
// there is no chance that we can decode the string without instantiating
// a temporary buffer, so quit this loop
if ((bb ^ '\\') < 1) break;
_tmp[i++] = (char) bb;
}
if (i == _tmp.length) {
final int newSize = chars.length * 2;
if (newSize > maxStringBuffer) {
throw newParseErrorWith("Maximum string buffer limit exceeded", maxStringBuffer);
}
_tmp = chars = Arrays.copyOf(chars, newSize);
}
_tmpLen = _tmp.length;
currentIndex = ci;
int soFar = --currentIndex - startIndex;
while (!isEndOfStream()) {
int bc = read();
if (bc == '"') {
return soFar;
}
if (bc == '\\') {
if (soFar >= _tmpLen - 6) {
final int newSize = chars.length * 2;
if (newSize > maxStringBuffer) {
throw newParseErrorWith("Maximum string buffer limit exceeded", maxStringBuffer);
}
_tmp = chars = Arrays.copyOf(chars, newSize);
_tmpLen = _tmp.length;
}
bc = buffer[currentIndex++];
switch (bc) {
case 'b':
bc = '\b';
break;
case 't':
bc = '\t';
break;
case 'n':
bc = '\n';
break;
case 'f':
bc = '\f';
break;
case 'r':
bc = '\r';
break;
case '"':
case '/':
case '\\':
break;
case 'u':
bc = (hexToInt(buffer[currentIndex++]) << 12) +
(hexToInt(buffer[currentIndex++]) << 8) +
(hexToInt(buffer[currentIndex++]) << 4) +
hexToInt(buffer[currentIndex++]);
break;
default:
throw newParseErrorWith("Invalid escape combination detected", bc);
}
} else if ((bc & 0x80) != 0) {
if (soFar >= _tmpLen - 4) {
final int newSize = chars.length * 2;
if (newSize > maxStringBuffer) {
throw newParseErrorWith("Maximum string buffer limit exceeded", maxStringBuffer);
}
_tmp = chars = Arrays.copyOf(chars, newSize);
_tmpLen = _tmp.length;
}
final int u2 = buffer[currentIndex++];
if ((bc & 0xE0) == 0xC0) {
bc = ((bc & 0x1F) << 6) + (u2 & 0x3F);
} else {
final int u3 = buffer[currentIndex++];
if ((bc & 0xF0) == 0xE0) {
bc = ((bc & 0x0F) << 12) + ((u2 & 0x3F) << 6) + (u3 & 0x3F);
} else {
final int u4 = buffer[currentIndex++];
if ((bc & 0xF8) == 0xF0) {
bc = ((bc & 0x07) << 18) + ((u2 & 0x3F) << 12) + ((u3 & 0x3F) << 6) + (u4 & 0x3F);
} else {
// there are legal 5 & 6 byte combinations, but none are _valid_
throw newParseErrorAt("Invalid unicode character detected", 0);
}
if (bc >= 0x10000) {
// check if valid unicode
if (bc >= 0x110000) {
throw newParseErrorAt("Invalid unicode character detected", 0);
}
// split surrogates
final int sup = bc - 0x10000;
_tmp[soFar++] = (char) ((sup >>> 10) + 0xd800);
_tmp[soFar++] = (char) ((sup & 0x3ff) + 0xdc00);
continue;
}
}
}
} else if (soFar >= _tmpLen) {
final int newSize = chars.length * 2;
if (newSize > maxStringBuffer) {
throw newParseErrorWith("Maximum string buffer limit exceeded", maxStringBuffer);
}
_tmp = chars = Arrays.copyOf(chars, newSize);
_tmpLen = _tmp.length;
}
_tmp[soFar++] = (char) bc;
}
throw newParseErrorAt("JSON string was not closed with a double quote", 0);
}
org.json
org.json.JSONTokener#nextString
public String nextString(char quote) throws JSONException {
char c;
StringBuilder sb = new StringBuilder();
for (;;) {
c = this.next();
switch (c) {
case 0:
case '\n':
case '\r':
throw this.syntaxError("Unterminated string");
case '\\':
c = this.next();
switch (c) {
case 'b':
sb.append('\b');
break;
case 't':
sb.append('\t');
break;
case 'n':
sb.append('\n');
break;
case 'f':
sb.append('\f');
break;
case 'r':
sb.append('\r');
break;
case 'u':
try {
sb.append((char)Integer.parseInt(this.next(4), 16));
} catch (NumberFormatException e) {
throw this.syntaxError("Illegal escape.", e);
}
break;
case '"':
case '\'':
case '\\':
case '/':
sb.append(c);
break;
default:
throw this.syntaxError("Illegal escape.");
}
break;
default:
if (c == quote) {
return sb.toString();
}
sb.append(c);
}
}
}
Johnzon
org.apache.johnzon.core.JsonStreamParserImpl#readString
private void readString() {
do {
char n = readNextChar();
//when first called n its first char after the starting quote
//after that its the next character after the while loop below
if (n == QUOTE_CHAR) {
endOfValueInBuffer = startOfValueInBuffer = bufferPos; //->"" case
return;
} else if (n == EOL) {
throw uexc("Unexpected linebreak");
} else if (/* n >= '\u0000' && */ n <= '\u001F') {
throw uexc("Unescaped control character");
} else if (n == ESCAPE_CHAR) {
n = readNextChar();
// \ u XXXX -> unicode char
if (n == 'u') {
n = parseUnicodeHexChars();
appendToCopyBuffer(n);
// \\ -> \
} else if (n == ESCAPE_CHAR) {
appendToCopyBuffer(n);
//another escape chars, for example \t
} else {
appendToCopyBuffer(Strings.asEscapedChar(n));
}
} else {
startOfValueInBuffer = bufferPos;
endOfValueInBuffer = -1;
while ((n = readNextChar()) > '\u001F' && n != ESCAPE_CHAR && n != EOL && n != QUOTE_CHAR) {
//read fast
}
endOfValueInBuffer = bufferPos;
if (n == QUOTE_CHAR) {
if (fallBackCopyBufferLength > 0) {
copyCurrentValue();
} else {
if ((endOfValueInBuffer - startOfValueInBuffer) > maxValueLength) {
throw tmc();
}
}
return;
} else if (n == EOL) {
throw uexc("Unexpected linebreak");
} else if (n >= '\u0000' && n <= '\u001F') {
throw uexc("Unescaped control character");
}
copyCurrentValue();
//current n is one of < '\u001F' -OR- ESCAPE_CHAR -OR- EOL -OR- QUOTE
unreadChar(); //unread one char
}
} while (true);
// before this do while(true) it was:
//
//recurse until string is terminated by a non escaped quote
//readString();
//
//
// but recursive = can't read big strings
}
0x14 RASP和JSON特性
综上所述,JSON解析有非常多的甚至是堪称离谱的解析特性,RASP必须支持以上列举的所有的特性解析,否则就可能导致防御被绕过的问题。值得注意的是,此类特性很难被完全覆盖,因此,RASP想要100%兼容JSON解析也绝非易事。目前已支持本文所有Payload的厂商有:安百 - 灵蜥、华胜久安 - 异龙RASP,2023年初已将规则同步给了边界无限 - 靖云甲,暂不知晓防御情况。至于其他厂商,HVV的时候可以自行测试,个人不希望捧高踩低,因此本文略过各厂商测试详情。